01 Feb 2026
요즘 온톨로지와 시맨틱 웹 관련 세미나나 강연을 진행하면서 자주 느끼는 점이 하나 있습니다. 바로 SPARQL을 소개할 때 청중들의 반응입니다.
SQL과 닮은 친구, SPARQL
SPARQL은 문법적으로 SQL과 매우 유사합니다. SELECT, WHERE, ORDER BY 같은 키워드를 사용하기 때문에, 개발 경험이 있는 분들은 처음에 굉장히 반가워하십니다. “아, 그냥 조인(Join) 많은 SQL이구나!”라고 받아들이는 경우가 많기 때문입니다.
하지만 강연을 계속 진행하다 보면, 바로 그 ‘익숙함’이 오히려 독이 되는 순간이 찾아옵니다.
유사함이 주는 오해
SQL은 닫힌 세계 가설(Closed World Assumption, CWA)을 전제로 합니다. 데이터베이스에 명시되지 않은 정보는 ‘거짓’이라고 간주하는 방식입니다. 예를 들어 수강생 목록에 ‘홍길동’이 없다면, 시스템은 “홍길동은 수강생이 아니다”라고 확신합니다.
반면, SPARQL과 온톨로지 세계관은 열린 세계 가설(Open World Assumption, OWA)을 따릅니다. 데이터에 정보가 없다고 해서 그것이 틀린 것이 아니라, 단지 ‘아직 모르는 상태’라고 판단합니다. “홍길동이 수강생이라는 데이터가 없다”는 사실이 “홍길동은 수강생이 아니다”라는 결론을 보장하지 않습니다. 어딘가 다른 데이터셋에 그 정보가 있을 수도 있고, 단지 아직 기록되지 않았을 뿐이라고 가정하기 때문입니다.
사실 테이블이냐 그래프냐 하는 구조적 차이보다, 이러한 철학적 전제의 차이가 쿼리 결과와 추론의 방향을 결정짓는 훨씬 더 본질적인 지점입니다.
SQL과 유사한 구문은 사용자로 하여금 관계형 데이터베이스(RDB)의 멘탈 모델을 온톨로지에 투영하게 만듭니다. 그러나 RDF 그래프 패턴 매칭은 관계 대수(Relational Algebra)를 기반으로 하는 SQL의 조인 연산과는 그 수학적 토대와 의미론적 해석이 근본적으로 다릅니다. 특히 OPTIONAL 연산의 비단조성(Non-monotonicity)이나 추론 규칙(Entailment Regimes)이 개입되는 지점에서 이러한 간극은 극대화됩니다. “왜 SQL과 동일하게 결과가 나오지 않는가?”라는 의문이 드는 순간, 역설적으로 그 익숙한 문법은 학습자가 시맨틱 웹의 고유한 논리 구조를 이해하는 데 방해가 되는 인지적 장벽으로 작용합니다.
차라리 완전히 다른 문법이라면?
그래서 최근에는 이런 고민을 하게 되었습니다. “차라리 온톨로지를 다루는 언어는 SQL과 완전히 다르게 생겼다고 처음부터 못 박는 게 낫지 않을까?”
RDB와는 아예 다른 사고방식이 필요하다는 것을 강조하기 위해, 문법적 유사성이 없는 언어로 접근하는 것이 ‘사고의 전환’을 유도하는 데 더 유리할 수 있다는 생각입니다.
여기서 소개하고 싶은 것이 바로 Datalog입니다.
Datalog: 논리 기반의 질의 언어
Datalog는 Prolog의 부분집합으로 시작된 선언형 논리 프로그래밍 언어입니다. 이름에서 알 수 있듯이 데이터(Data)와 논리(Logic)를 다루는 데 특화되어 있습니다.
SPARQL이 데이터베이스로부터 명시적인 데이터를 조회(Querying)하는 데 중점을 둔다면, Datalog는 주어진 사실(Facts)과 규칙(Rules)으로부터 새로운 지식을 도출(Inference)하는 패러다임을 따릅니다. 이는 온톨로지의 핵심인 추론(Reasoning) 메커니즘과 논리적으로 일관된 구조를 가집니다.
Datalog의 맛보기
예를 들어, “조상의 조상은 조상이다”라는 재귀적인 관계를 SPARQL로 표현하려면 (SPARQL 1.1의 Property Path가 있긴 하지만) 꽤나 설명이 길어질 수 있습니다. 하지만 Datalog에서는 매우 직관적인 논리 규칙으로 표현됩니다.
ancestor(X, Y) :- parent(X, Y).
ancestor(X, Y) :- parent(X, Z), ancestor(Z, Y).
X가 Y의 부모라면, X는 Y의 조상입니다.X가 Z의 부모이고, Z가 Y의 조상이라면, X는 Y의 조상입니다.
이 문법은 SQL과는 전혀 다릅니다. 그렇기 때문에 학습자는 RDB의 사고방식을 내려놓고, 논리적 관계와 사실의 도출이라는 새로운 관점에서 데이터를 바라보게 됩니다.
결론
물론 현실의 시맨틱 웹 생태계 표준은 SPARQL입니다. 하지만 온톨로지의 본질인 ‘지식의 표현과 추론’을 이해하기 위한 입문 도구로서, 혹은 SPARQL이 주는 RDB의 환상을 깨기 위한 충격 요법으로서 Datalog를 먼저 접해보는 것은 꽤나 매력적인 시도가 될 것 같습니다.
마지막으로, 앞서 이야기한 세 가지 언어의 기술적 특성을 간단히 비교해보면 다음과 같습니다.
| 특성 |
SQL |
SPARQL |
Datalog |
| 데이터 모델 |
테이블 (Relational Table) |
그래프 (RDF Graph) |
사실(Facts) 및 규칙(Rules) |
| 기본 전제 |
닫힌 세계 가설 (CWA) |
열린 세계 가설 (OWA) |
논리적 귀결 (Logical Consequence) |
| 핵심 연산 |
관계 대수 (Relational Algebra) |
그래프 패턴 매칭 (Pattern Matching) |
재귀적 추론 (Recursive Inference) |
| 주요 목적 |
데이터의 관리 및 조회 |
웹 데이터의 연결 및 탐색 |
지식의 표현 및 새로운 사실 도출 |
SQL의 그늘에서 벗어나, 데이터 그 자체의 논리적 연결에 집중하게 해주는 Datalog. 온톨로지를 공부하다가 SPARQL의 문법적 함정에 빠져 허우적거린 경험이 있으시다면, 한 번쯤 눈길을 돌려볼 만한 가치가 있습니다.
31 Jan 2026
딥러닝과 대규모 언어 모델(LLM)의 확산으로 인해 고성능 컴퓨팅의 중심이 GPU로 이동하고 있지만, RDF(Resource Description Framework) 데이터 처리와 SPARQL 쿼리 실행 영역에서는 여전히 CPU의 성능과 대규모 메모리 아키텍처가 시스템의 효율성을 결정짓는 핵심 요소입니다.
1. RDF 처리의 특성: 랜덤 액세스 패턴
GPU가 빛을 발하는 영역은 대규모 병렬 연산입니다. 정형화된 데이터를 대상으로 동일한 연산을 수천 개의 데이터에 동시에 적용하는 작업에서는 GPU가 압도적입니다. 그러나 RDF와 그래프 데이터베이스는 데이터 간의 연결을 따라가는 비정형적인 탐색이 주를 이루므로 성격이 근본적으로 다릅니다.
그래프 탐색의 본질
RDF 데이터는 트리플(Subject-Predicate-Object) 형태로 저장되어 거대한 그래프를 형성합니다. SPARQL 쿼리를 실행한다는 것은 이 그래프를 탐색(Traversal)하는 것입니다.
문제는 그래프 탐색이 랜덤 액세스 패턴을 따른다는 점입니다. A 노드에서 B 노드로, B에서 또 다른 C 노드로 점프하는 과정에서 메모리 접근이 예측 불가능하게 분산됩니다. GPU는 순차적이고 예측 가능한 메모리 접근에 최적화되어 있어, 이러한 랜덤 패턴에서는 오히려 비효율적입니다 [1].
2. 메모리 용량의 결정적 차이
GPU 메모리의 한계
RDF 트리플 스토어는 효율적인 쿼리를 위해 다중 인덱스를 유지합니다. 기본 트리플 구조(S, P, O)에서는 6가지 순열(SPO, SOP, PSO, POS, OSP, OPS)이 가능하지만, 네임드 그래프(Named Graph)를 포함하는 쿼드(Quad) 구조(G, S, P, O)로 확장되면 상황은 훨씬 복잡해집니다.
이론적으로 4개의 요소는 총 24가지(4!)의 순열을 가질 수 있으며, 실무적인 성능을 위해 GSPO, GPOS, GOSP, SPOG, GSOP 등 주요 접근 패턴에 대한 인덱스를 중복해서 생성합니다 [2]. 여기에 문자열을 ID로 변환하는 딕셔너리 인코딩 구조까지 포함하면, 전체 인덱스 크기는 원본 데이터 대비 5~10배 이상으로 증폭됩니다.
NVIDIA H100도 80GB 정도의 메모리를 가지고 있습니다. 반면, 서버급 CPU 시스템은 수백 GB에서 TB 단위의 메모리를 장착할 수 있습니다.
수십억 개의 트리플을 처리할 때 이 거대한 데이터를 80GB 내외의 GPU 메모리에 담는 것은 구조적으로 한계가 있습니다.
대규모 Knowledge Graph(예: Wikidata, DBpedia)를 다룬다면, GPU 메모리에 전체 그래프를 올리는 것 자체가 불가능합니다. “필요한 부분만 디스크에서 읽어오면 되지 않느냐”고 생각할 수 있지만, 앞서 언급한 랜덤 액세스 특성 때문에 인덱스의 일부만 메모리에 올리는 방식은 I/O 병목 현상을 극심하게 유발합니다. 결국 고성능 SPARQL 엔진은 전체 인덱스를 메모리에 상주시키는 ‘In-memory’ 방식을 선호하게 되는데, GPU는 이 지점에서 메모리 용량이라는 물리적 한계에 부딪히게 됩니다.
CPU-GPU 데이터 전송 오버헤드
GPU를 사용하더라도 데이터는 CPU 메모리에서 GPU 메모리로 PCIe 버스를 통해 전송되어야 합니다. 이 전송 오버헤드가 실제 연산 시간보다 길어지는 경우가 많습니다 [3].
특히 SPARQL 쿼리가 그래프의 다양한 영역을 탐색해야 할 때, 필요한 데이터를 GPU로 계속 옮겨야 하므로 GPU 연산의 이점이 상쇄됩니다.
3. SPARQL 쿼리 처리의 CPU 친화적 특성
조인 연산과 쿼리 최적화
SPARQL 쿼리의 핵심은 트리플 패턴 매칭과 이를 연결하는 조인(Join) 연산입니다. 일반적인 SQL 조인이 미리 정의된 외래 키(Foreign Key)를 따라 테이블을 결합하는 방식이라면, SPARQL의 조인은 쿼리 실행 시점에 공유 변수(Variable)를 매개로 그래프 패턴을 확장해 나가는 과정입니다. 복잡한 쿼리는 수십 개의 트리플 패턴을 조인해야 하며, 이때 데이터의 카디널리티(Cardinality, 특정 패턴에 매칭되는 결과의 수)를 예측하여 최적의 조인 순서를 결정하는 것이 성능에 결정적입니다 [4].
쿼리 최적화(Query Optimization)는 본질적으로 순차적이고 복잡한 의사결정 과정입니다. 각 단계의 결과가 다음 단계의 입력이 되므로, GPU의 병렬 처리 능력을 활용하기 어렵습니다. 현대의 고성능 CPU가 제공하는 브랜치 예측(Branch Prediction)과 캐시 최적화가 훨씬 효과적입니다.
추론(Reasoning)의 복잡성
RDF의 강점 중 하나는 온톨로지 기반 추론(Reasoning)입니다. OWL이나 RDFS 시맨틱스에 따라 암시적 지식을 도출하는 과정은 논리적 규칙의 반복 적용을 필요로 합니다 [5].
이 과정은 GPU가 잘하는 “같은 연산의 대량 반복”이 아니라, “조건에 따른 분기가 빈번한 복잡한 로직”입니다. CPU의 복잡한 명령 파이프라인과 분기 예측이 이런 워크로드에 훨씬 적합합니다.
4. 실무적 권장사항
메모리: 다다익선
인메모리 트리플 스토어(예: Apache Jena, GraphDB)를 사용한다면, 메모리야말로 성능의 핵심입니다. 전체 그래프와 인덱스를 메모리에 올릴 수 있다면 쿼리 응답 시간이 극적으로 개선됩니다.
권장사항:
- 중소 규모(수천만 트리플): 64GB 이상
- 대규모(수억 트리플): 256GB 이상
- 엔터프라이즈급(십억 트리플 이상): 1TB 이상 또는 분산 클러스터
CPU: 코어 수보다 단일 코어 성능
많은 분들이 코어 수가 많은 CPU를 선택하지만, SPARQL 쿼리 대부분은 단일 쿼리 단위로 처리됩니다. 동시에 수십 개의 쿼리를 처리해야 하는 경우가 아니라면, 높은 클럭 속도와 큰 L3 캐시를 가진 CPU가 더 효과적입니다.
권장사항:
- 대형 L3 캐시(64MB 이상)를 가진 서버급 CPU
- 메모리 대역폭이 높은 DDR5 지원 플랫폼
- 단일 코어 성능이 중요하므로 무조건적인 코어 수 늘리기는 비효율적
GPU는 특수한 경우에만
물론 GPU가 유리한 RDF 관련 작업도 있습니다:
- 그래프 임베딩 학습 (Knowledge Graph Embedding)
- 대규모 유사도 계산 (Entity Matching)
- 대규모 병렬 조인: 일반적인 SPARQL 조인과 달리, 데이터가 정형화되어 있고 수백만 개의 트리플을 동시에 결합해야 하는 특정 분석용 쿼리(예: 대규모 해시 조인)에서는 GPU의 SIMD(Single Instruction, Multiple Data) 연산이 성능을 높일 수 있습니다 [6].
하지만 다시 강조하지만, 일반적인 SPARQL 쿼리 서빙과 추론에서는 CPU와 메모리 투자가 훨씬 효율적입니다.
5. 결론
RDF 처리 시스템을 구축할 때, GPU 카드를 구매하기 전에 먼저 질문해야 합니다:
“메모리는 충분한가? CPU는 적절한가?”
그래프 데이터의 랜덤 액세스 패턴, 메모리 집약적 인덱싱, 복잡한 추론 로직이라는 세 가지 특성이 CPU와 메모리를 핵심 병목으로 만듭니다. 예산이 한정되어 있다면, 고성능 GPU보다 더 많은 메모리와 캐시가 큰 CPU에 투자하는 것이 현명한 선택입니다.
딥러닝 시대에 GPU가 만능처럼 느껴지지만, 모든 문제가 행렬 연산은 아닙니다. 문제의 본질을 이해하고 그에 맞는 하드웨어를 선택하는 것이야말로 엔지니어의 역할입니다.
참고문헌
- [1]S. Beamer, K. Asanovic, and D. Patterson, “Direction-Optimizing Breadth-First Search,” in 2012 International Conference on High Performance Computing, Networking, Storage and Analysis (SC), IEEE, 2012, pp. 1–10.
- [2]M. Atre, V. Chaoji, M. J. Zaki, and J. A. Hendler, “Matrix ‘Bit’ loaded: a scalable lightweight join query processor for RDF data,” Proceedings of the 19th International Conference on World Wide Web (WWW), pp. 41–50, 2010.
- [3]C. Chantrapornchai and C. Choksuchat, “GPU-based SPARQL Query Processing,” Walailak Journal of Science and Technology, vol. 15, no. 7, pp. 521–537, 2018.
- [4]A. Hogan and others, “Knowledge Graphs,” ACM Computing Surveys, vol. 54, no. 4, pp. 1–37, 2021.
- [5]Ontotext, “What is RDF Reasoning?” 2024. Available at: https://www.ontotext.com/knowledgehub/fundamentals/what-is-rdf-reasoning/
- [6]P. Yuan, P. Liu, J. Zhai, L. Wu, H. Liu, and H. Jin, “TripleBit: A Fast and Compact System for Large Scale RDF Data,” in Proceedings of the VLDB Endowment, 2013, pp. 517–528.
29 Jan 2026
현재 제가 운행 중인 쉐보레 콜로라도는 덩치도 크고 공간도 넓어서 다방면으로 정말 유용하게 잘 활용하고 있는 차량입니다. 특히 요즘에는 출퇴근용으로 매일같이 운행하고 있는데, 최근 들어 부쩍 배터리 방전이 잦아졌습니다. 아침마다 출근하려는데 시동이 걸리지 않아 직접 점프 스타트 장비를 연결해 시동을 거는 일이 반복되다 보니, 여간 번거로운 것이 아니었습니다.

이제 4년 차에 접어든 차량이라 배터리 수명 자체가 완전히 다했다고 보기에는 기간이 조금 짧은 듯한 느낌이 들었습니다. 보통 배터리 교체 주기를 생각하면 조금 더 사용할 수 있어야 하는데, 자꾸 방전이 반복되는 것을 보며 결국 제 운행 패턴에 문제가 있는 것이 아닐까 하는 의구심이 생겼지만 운행 패턴을 하루아침에 바꾸는 것은 현실적으로 불가능한 일이었습니다. 결국 환경을 바꿀 수 없다면, 저의 가혹한(?) 운행 환경을 충분히 감당해낼 수 있는 적합한 배터리로 교체하는 것이 해결책이라는 결론을 내리게 되었습니다.
가설 수립 및 검증
교체할 배터리를 선택하기에 앞서, 제 운행 환경을 분석하고 가설을 세워보았습니다.
- 운행 패턴: 하루 2회 운행. 90%는 10분 이내의 단거리 주행, 10% 정도만 비정기적인 1시간 이상 주행.
- 문제 현상: 일주일에 한 번 정도 방전 발생 (70Ah 순정 배터리 기준).
- 가설: 시동 시 소모된 전력을 10분 미만의 짧은 주행으로는 알터네이터가 충분히 보충하지 못한다. 여기에 블랙박스 주차 모드 등의 암전류가 더해져 배터리 잔량(SoC)이 계단식으로 하락할 것이다. 용량을 키우면 이 하락 기울기를 버티는 버퍼가 커져 방전 주기를 늦출 수 있을 것이다.
이 가설을 검증하기 위해 파이썬으로 초 단위(Second-by-second) 시뮬레이션을 수행해보았습니다. 특히 배터리 잔량이 시동 한계(약 20Ah) 이하로 떨어지면 ‘점프 스타트’를 통해 외부 전원으로 시동을 걸고 충전을 시작한다는 현실적인 시나리오를 적용했습니다.
import matplotlib.pyplot as plt
import numpy as np
import random
def simulate_battery_second_by_second(capacity_ah, days=30, charge_efficiency=1.0):
# Time step: 1 second
total_seconds = days * 24 * 3600
# Parameters
current_charge_ah = capacity_ah
# Threshold for Cranking (Below this, we need a jump start)
# Fixed 20Ah needed to crank safely
min_start_threshold_ah = 20.0
# Current Draw / Charge rates (Amps)
parasitic_drain_amp = 0.35 # Parking mode
alternator_charge_amp = 20.0 # Effective charge during drive
# Start consumption (Ah per start)
start_cost_ah = 0.2
# Trip Config
# Define approximate start times for trips (e.g., 8am and 6pm) in seconds from midnight
trip_start_times_sec = [8 * 3600, 18 * 3600]
# Pre-calculate trip schedule for the entire period to save processing time
# We will store events as a list of (start_second, duration_seconds)
trip_events = []
for day in range(days):
day_offset = day * 24 * 3600
for start_time_local in trip_start_times_sec:
# Add some randomness to start time (+/- 30 mins)
actual_start = day_offset + start_time_local + random.randint(-1800, 1800)
# Determine duration
# 90% short trips (5-10 mins)
# 10% long trips (Normal dist: mean=60m, std=10m)
if random.random() < 0.9:
# Uniform 5~10 mins
duration_min = random.uniform(5, 10)
else:
# Normal distribution 60 mins
duration_min = np.random.normal(60, 10)
if duration_min < 5: duration_min = 5 # Clamp min
duration_sec = int(duration_min * 60)
trip_events.append((actual_start, duration_sec))
# Sort events just in case
trip_events.sort()
history_hours = []
history_soc = []
jump_start_events = [] # To track when jump starts happened
# To speed up, we can calculate state between events instead of looping every second
# State 0: Parking
# State 1: Driving
evt_idx = 0
num_events = len(trip_events)
current_time = 0
# Record history every hour (3600 ticks) for plotting resolution
record_interval = 3600
next_record_time = 0
while current_time < total_seconds:
# Determine next event start
if evt_idx < num_events:
next_evt_start, next_evt_duration = trip_events[evt_idx]
else:
next_evt_start = total_seconds + 1 # End of sim
# 1. PARKING Phase (current_time -> next_evt_start)
parking_duration = next_evt_start - current_time
# Calculate drain for this parking block
# Check if we cross recording intervals
# Simplified loop for recording resolution
while current_time < next_evt_start and current_time < total_seconds:
step = min(record_interval, next_evt_start - current_time)
# Apply Drain
# Ah = Amps * Hours
drain_ah = parasitic_drain_amp * (step / 3600.0)
current_charge_ah -= drain_ah
# Clamp min to start threshold (User logic: cannot go below failure point)
if current_charge_ah < min_start_threshold_ah:
current_charge_ah = min_start_threshold_ah
current_time += step
# Record if we hit a boundary (approx)
if current_time >= next_record_time:
history_hours.append(current_time / 3600.0)
history_soc.append(current_charge_ah)
next_record_time += record_interval
if evt_idx >= num_events:
break
# 2. DRIVING Phase (Start + Charge)
# Check if we have enough juice to start
if current_charge_ah <= min_start_threshold_ah:
# JUMP START SCENARIO
# External power used. No drain.
# Ensure we start at least at the threshold
current_charge_ah = min_start_threshold_ah
jump_start_events.append(current_time / 3600.0)
else:
# NORMAL START SCENARIO
current_charge_ah -= start_cost_ah
# Check floor again just in case start cost dips it
if current_charge_ah < min_start_threshold_ah:
current_charge_ah = min_start_threshold_ah
# If start cost dipped it, technically it failed to start without help?
# But let's assume it cranked barely.
# Charge during drive
# We assume driving happens instantly for the sake of the 'while' loop step,
# or we integrate it. Let's integrate it.
drive_end_time = current_time + next_evt_duration
while current_time < drive_end_time and current_time < total_seconds:
step = min(record_interval, drive_end_time - current_time)
# Apply Charge (Modified by Efficiency)
charge_ah = (alternator_charge_amp * charge_efficiency) * (step / 3600.0)
current_charge_ah += charge_ah
# Clamp max
if current_charge_ah > capacity_ah: current_charge_ah = capacity_ah
current_time += step
if current_time >= next_record_time:
history_hours.append(current_time / 3600.0)
history_soc.append(current_charge_ah)
next_record_time += record_interval
evt_idx += 1
return history_hours, history_soc, jump_start_events
def run_capacity_simulation():
days = 30
capacities = [70, 80, 90]
colors = {70: '#ff4d4d', 80: '#ffca28', 90: '#66bb6a'}
plt.figure(figsize=(10, 6))
seed_val = 42
for cap in capacities:
random.seed(seed_val)
np.random.seed(seed_val)
hours, soc, jumps = simulate_battery_second_by_second(cap, days, charge_efficiency=1.0)
plt.plot(hours, soc, label=f'{cap}Ah Battery', color=colors[cap], linewidth=1.5)
# Mark jump starts with an 'x'
if jumps:
plt.scatter(jumps, [soc[int(t)] for t in [min(int(j), len(soc)-1) for j in jumps] if int(t) < len(soc)],
color=colors[cap], marker='x', s=50, zorder=5) # Crude approx for Y pos
# Plot risk threshold line (Fixed 20Ah)
plt.axhline(y=20, color='gray', linestyle='--', alpha=0.5, label='Start Threshold (20Ah)')
plt.title('Battery SoC Simulation: Capacity Difference (Efficiency 100%)')
plt.xlabel('Hours Passed (30 Days)')
plt.ylabel('State of Charge (Ah)')
plt.grid(True, linestyle=':', alpha=0.6)
plt.legend()
plt.tight_layout()
output_path = 'battery_simulation.png'
plt.savefig(output_path, dpi=150)
print(f"Capacity Simulation graph saved to {output_path}")
def run_efficiency_simulation():
days = 30
capacity = 95
scenarios = [
{'type': 'Standard Lead-Acid', 'eff': 0.7, 'color': '#ff4d4d'},
{'type': 'AGM Battery', 'eff': 0.9, 'color': '#007bff'}
]
plt.figure(figsize=(10, 6))
seed_val = 42 # Same driving pattern
for sc in scenarios:
random.seed(seed_val)
np.random.seed(seed_val)
hours, soc, jumps = simulate_battery_second_by_second(capacity, days, charge_efficiency=sc['eff'])
label_text = f"95Ah {sc['type']} (Eff: {int(sc['eff']*100)}%)"
plt.plot(hours, soc, label=label_text, color=sc['color'], linewidth=2)
if jumps:
plt.scatter(jumps, [soc[int(t)] for t in [min(int(j), len(soc)-1) for j in jumps] if int(t) < len(soc)],
color=sc['color'], marker='x', s=50, zorder=5)
plt.axhline(y=20, color='gray', linestyle='--', alpha=0.5, label='Start Threshold (20Ah)')
plt.title('Battery SoC Simulation: Charging Efficiency (Standard vs AGM)')
plt.xlabel('Hours Passed (30 Days)')
plt.ylabel('State of Charge (Ah)')
plt.grid(True, linestyle=':', alpha=0.6)
plt.legend()
plt.tight_layout()
output_path = 'charging_efficiency_simulation.png'
plt.savefig(output_path, dpi=150)
print(f"Efficiency Simulation graph saved to {output_path}")
if __name__ == "__main__":
# We display the run logic here, but in the blog we might hide the main block or show it.
# The snippet in the blog shows up to the functions.
run_capacity_simulation()
run_efficiency_simulation()
시뮬레이션 결과(30일 추이)는 다음과 같습니다.
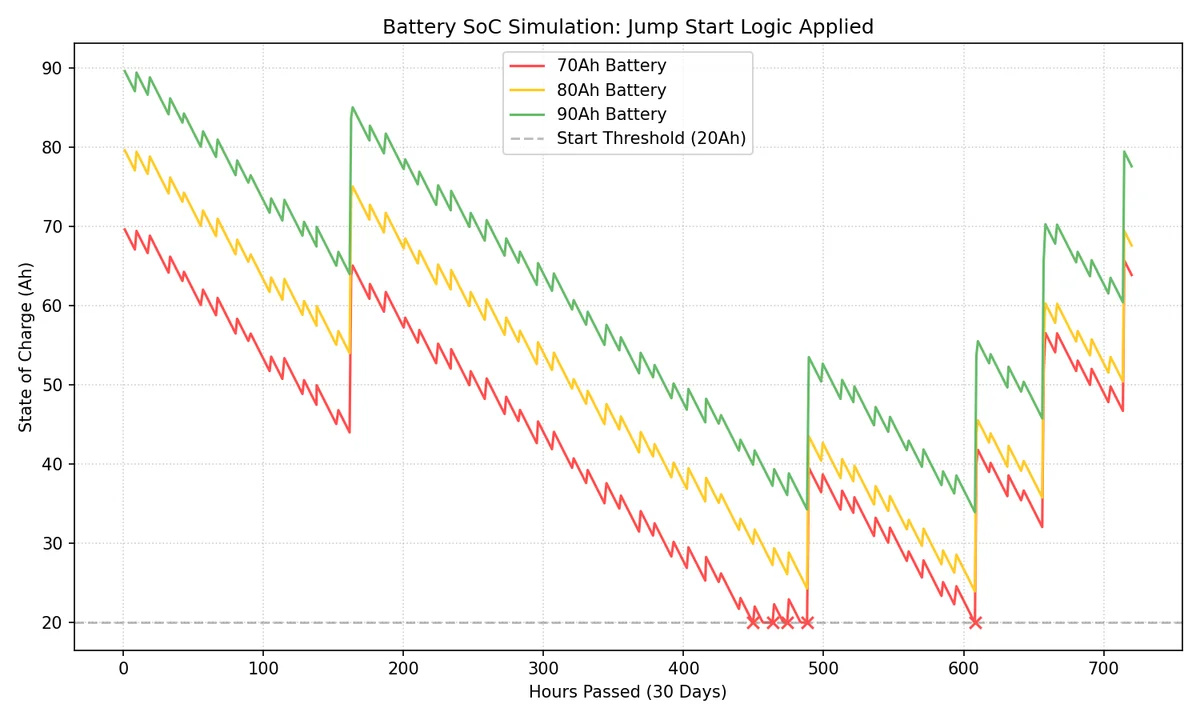
그래프를 보면 70Ah 배터리(적색)는 주차 중 암전류로 인해 잔량이 지속적으로 감소하다가, 시동 한계선(20Ah)에 도달하면 더 이상 내려가지 않고 멈춥니다(점프 스타트 개입). 이후 주행을 통해 잠시 회복하지만 곧 다시 바닥으로 떨어지는 위태로운 모습을 보입니다. 반면 90Ah 배터리(녹색)는 동일한 조건에서도 여유 있는 용량 덕분에 한계선 위에서 안정적으로 사이클을 유지합니다.
충전 효율의 점검
단순히 배터리 용량만 키운다고 해서 모든 문제가 해결될지 의문이 들었습니다. 충전이 소모를 따라가지 못하는 근본적인 환경이라면, 결국 큰 배터리도 방전 시점만 늦출 뿐이기 때문입니다. 그래서 한 가지 더 확인해보고 싶었던 것이 바로 충전 효율입니다. 짧은 주행 시간 동안 얼마나 효율적으로 에너지를 받아들일 수 있는지, 효율 변수를 조정하여 다시 한번 시뮬레이션을 진행해 보았습니다.
일반적인 납산 배터리의 충전 효율(Coulombic Efficiency)은 약 70%~85% 수준입니다. 즉, 시동 시 소모된 1Ah를 복구하기 위해 발전기는 약 1.2~1.4Ah 이상의 에너지를 밀어넣어야 합니다. 하지만 단거리 주행에서는 배터리 내부 저항으로 인해 전하를 받아들이는 속도가 제한되어, 실제 충전량은 시뮬레이션보다 더 낮을 가능성이 큽니다.
차량용 배터리 타입별 충전 성능을 비교하면 다음과 같습니다.
| 배터리 타입 |
예상 충전 효율 |
특징 |
| 일반 납산 (Flooded) |
약 70% ~ 85% |
표준적인 성능 |
| EFB (Enhanced Flooded) |
약 85% ~ 90% |
납산 배터리의 내구성을 보완 |
| AGM (Absorbent Glass Mat) |
약 90% 이상 |
충전 속도가 매우 빠르고 저온 시동성이 뛰어남 |
일단 국내 쇼핑몰을 검색하니, EFB는 거의 없고 AGM만이 대부분이었습니다. 그래서 AGM으로 교체하는 것이 현실적인 선택이 될것이라고 생각하고 다시 시뮬레이션을 진행해 보았습니다.
시뮬레이션 결과는 다음과 같습니다.
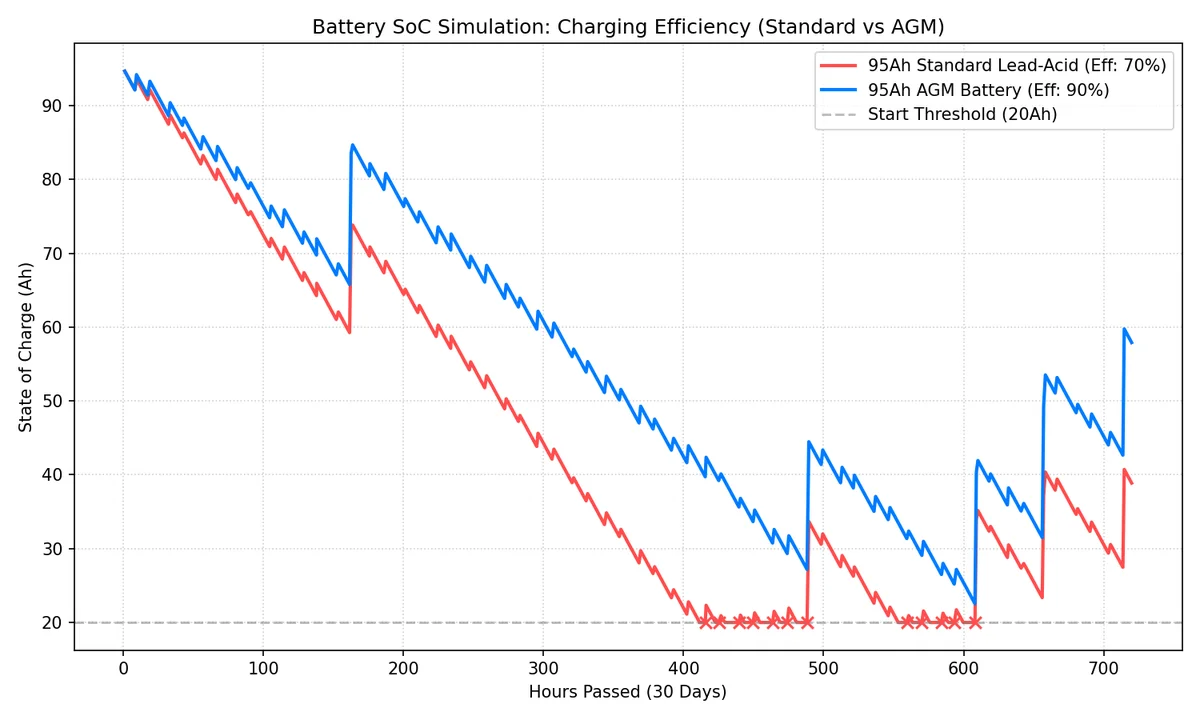
그래프를 보면 95Ah 납산 배터리(적색, 효율 70%)는 용량은 크지만 충전 속도가 따라가지 못해 결국 방전 위험선에 도달하는 반면, 95Ah AGM 배터리(청색, 효율 90%)는 빠른 충전 회복력 덕분에 훨씬 안정적인 잔량을 유지할 것을 기대할 수 있습니다.
교체 시작
실은 그냥 AGM 배터리로 교체할 당위성을 확보하기 위해서 근거 자료를 확보한 것뿐입니다. 생각보다 무겁고 비싼 배터리를 구매하는데 스스로 설득하기 위한 시뮬레이션이었습니다. 주문후 도착한 배터리를 교체하기 위해서 공구를 챙겨서 주차장으로 내려왔습니다.

쉐비 콜로라도 배터리 고정 너트를 풀기 위해서는 13mm 복스(소켓)이 필요합니다. 그 외에는 장갑과 일자 드라이버 정도가 있으면 좋을듯 합니다.
교체 작업 순서
배터리 교체의 기본 원칙은 다음과 같습니다:
- 제거할 때: 마이너스(-) 먼저, 그 다음 플러스(+)
- 장착할 때: 플러스(+) 먼저, 그 다음 마이너스(-)
차량용 배터리의 전압이 12V이기에, 간과할 수 있지만 전류가 매우 높기 때문에 위 순서가 매우 중요합니다. 혹시라도 반대로 하신다면 불꽃이 보이거나, 단자가 열로 인하여 붙는 현상이 발생할 수 있고, 깜짝 놀랄 수 있습니다.
1. 기존 배터리 제거
먼저 본넷을 열고 배터리 위치를 확인합니다.


이제 배터리 마이너스 단자와 플러스 단자를 풀러줍니다.


이제 배터리를 차체에 고정하고 있는 브라켓을 13mm 복스를 이용해 풀어줍니다. 보통 배터리 하단 깊숙한 곳에 있는데, 콜로라도는 그냥 위에 있습니다. T 복스라고 해서 엄청 기다란 도구가 필요할 줄 알았는데, 그냥 일반 스패너로도 풀리는 위치에 있었습니다.
배터리 브라켓을 풀고 나면, 엄청나게 무거운 배터리를 들어 올려 탈거할 수 있습니다.

2. 새 배터리 장착
새 배터리의 포장을 뜯어 장착을 준비했습니다. 기존 납산 배터리보다 용량이 더 크니, 무게도 더 무겁고 크기도 더 큽니다. 다행인건 배터리 자체에 손잡이가 있어서 혼자서 간신히 들수 있었습니다.

규격이 조금 달라졌지만 트레이에 여유가 있어서 잘 들어갈 수 있었습니다. 다만, 전선들이 얽혀있어서 조금 정리가 필요했습니다.


3. 단자 연결 및 브라켓 고정
단자가 단단히 고정되었는지 흔들어보고, 브라켓까지 고정하여 마무리합니다.


마무리
정말 다행이도 교체 후 시동이 걸렸습니다. 이제는 수행해본 시뮬레이션이 제대로 맞는지 검증해보는 일만 남았습니다.